Una Red Neuronal Generativa Adversarial (GAN) es un tipo de modelo de aprendizaje profundo utilizado en la generación de datos, como imágenes, música, texto, entre otros. Una GAN consta de dos redes neuronales, que son esencialmente dos modelos que se entrenan juntos pero tienen objetivos opuestos:
- Generador (Generator): La primera red es el generador, que tiene como tarea crear datos que sean indistinguibles de los datos reales. En el contexto de imágenes, el generador toma como entrada un vector de ruido aleatorio y genera una imagen que debería parecerse a las imágenes reales del conjunto de datos que se está utilizando. Su objetivo es producir datos falsos que sean lo más realistas posible.
- Discriminador (Discriminator): La segunda red es el discriminador, que actúa como un clasificador binario. Su tarea es determinar si una entrada es real (proveniente del conjunto de datos original) o falsa (generada por el generador). El objetivo del discriminador es separar correctamente los datos reales de los generados por el generador.
El proceso de entrenamiento de una GAN implica una competencia entre el generador y el discriminador. El generador intenta producir datos que sean cada vez más difíciles de distinguir de los datos reales, mientras que el discriminador intenta mejorar su capacidad para hacer esta distinción. Ambas redes se entrenan simultáneamente y, en última instancia, el generador debe llegar a ser lo suficientemente bueno como para generar datos que el discriminador no pueda distinguir de los datos reales.
Una vez que la GAN se entrena con éxito, el generador se puede utilizar para crear nuevos datos que sean similares a los datos de entrenamiento originales. Esto se ha utilizado en diversas aplicaciones, como generación de imágenes, mejora de resolución de imágenes, síntesis de voz, creación de texto y mucho más.
Código de Ejemplo:
import tensorflow as tf
from tensorflow.keras.layers import Dense, Flatten, Reshape
from tensorflow.keras.models import Sequential
import numpy as np
import matplotlib.pyplot as plt
# Datos de entrenamiento (MNIST, números escritos a mano)
(x_train, _), (_, _) = tf.keras.datasets.mnist.load_data()
x_train = x_train / 127.5 - 1.0
x_train = x_train.reshape(x_train.shape[0], 784)
# Tamaño del espacio latente (z)
latent_dim = 100
# Construir el generador
generator = Sequential()
generator.add(Dense(256, input_dim=latent_dim, activation='relu'))
generator.add(Dense(784, activation='tanh'))
# Construir el discriminador
discriminator = Sequential()
discriminator.add(Dense(256, input_dim=784, activation='relu'))
discriminator.add(Dense(1, activation='sigmoid'))
# Compilar el discriminador
discriminator.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# Congelar el discriminador durante el entrenamiento del generador
discriminator.trainable = False
# Construir la GAN
gan = Sequential([generator, discriminator])
gan.compile(loss='binary_crossentropy', optimizer='adam')
# Función para entrenar la GAN
def train_gan(gan, generator, discriminator, x_train, latent_dim, n_epochs=10000, batch_size=64):
for epoch in range(n_epochs):
# Entrenar el discriminador
idx = np.random.randint(0, x_train.shape[0], batch_size)
real_images = x_train[idx]
labels = np.ones((batch_size, 1))
fake_images = generator.predict(np.random.normal(0, 1, (batch_size, latent_dim)))
d_loss_real = discriminator.train_on_batch(real_images, labels)
labels = np.zeros((batch_size, 1))
d_loss_fake = discriminator.train_on_batch(fake_images, labels)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# Entrenar la GAN (generador)
labels = np.ones((batch_size, 1))
g_loss = gan.train_on_batch(np.random.normal(0, 1, (batch_size, latent_dim)), labels)
# Mostrar el progreso
if epoch % 100 == 0:
print(f"Epoch: {epoch}, D Loss: {d_loss[0]}, G Loss: {g_loss}")
# Guardar imágenes generadas
if epoch % 1000 == 0:
generate_and_save_images(generator, epoch)
# Función para generar y guardar imágenes generadas
def generate_and_save_images(model, epoch, examples=10, dim=(1, 10), figsize=(10, 1)):
noise = np.random.normal(0, 1, (examples, latent_dim))
generated_images = model.predict(noise)
generated_images = 0.5 * generated_images + 0.5
plt.figure(figsize=figsize)
for i in range(examples):
plt.subplot(dim[0], dim[1], i + 1)
plt.imshow(generated_images[i].reshape(28, 28), interpolation='nearest', cmap='gray')
plt.axis('off')
plt.tight_layout()
plt.savefig(f'gan_generated_image_epoch_{epoch}.png')
plt.show()
# Entrenar la GAN
train_gan(gan, generator, discriminator, x_train, latent_dim)
El código anterior entrena una GAN para generar imágenes de dígitos escritos a mano. La GAN consta de un generador y un discriminador, y se entrenan de manera adversarial. La función train_gan realiza el entrenamiento de la GAN, mientras que generate_and_save_images genera y guarda imágenes generadas a lo largo del proceso de entrenamiento.
Aquí una explicación más detallada:
- Datos de Entrenamiento: Los datos de entrenamiento provienen del conjunto de datos MNIST, que contiene imágenes en escala de grises de números escritos a mano (dígitos del 0 al 9). Estas imágenes se escalan para que los valores de los píxeles estén en el rango de -1 a 1 y se aplanan a un vector de 784 dimensiones.
- Generador (Generator): El generador es una red neuronal que toma un vector de ruido (el espacio latente) como entrada y genera imágenes falsas. En este caso, consta de dos capas densas: una capa de entrada con 256 unidades y activación ReLU, y una capa de salida con 784 unidades y activación tangente hiperbólica (tanh). El generador toma muestras aleatorias del espacio latente y produce imágenes de dígitos.
- Discriminador (Discriminator): El discriminador es otra red neuronal que actúa como un clasificador binario. Toma una imagen (real o falsa) como entrada y debe distinguir si la imagen es real o falsa. Está formado por dos capas densas: una capa de entrada con 256 unidades y activación ReLU, y una capa de salida con una unidad y activación sigmoide. La salida se interpreta como la probabilidad de que la imagen sea real.
- Compilación del Discriminador: El discriminador se compila con una función de pérdida de entropía cruzada binaria (binary_crossentropy) y el optimizador Adam. Se ajusta para distinguir entre imágenes reales y falsas.
- Congelación del Discriminador: Para el entrenamiento de la GAN, el discriminador se congela y no se entrena mientras se entrena el generador. Esto significa que el discriminador no se actualiza con el generador, lo que permite que el generador aprenda a generar imágenes que engañen al discriminador.
- Construcción de la GAN: La GAN se crea combinando el generador y el discriminador en una secuencia. La GAN se compila con la misma función de pérdida de entropía cruzada binaria y el optimizador Adam.
- Función de Entrenamiento: La función
train_ganes donde ocurre el entrenamiento de la GAN. Durante cada iteración, se entrena primero el discriminador para distinguir entre imágenes reales y falsas. Luego, se entrena la GAN para engañar al discriminador y hacer que crea que las imágenes generadas son reales. Esto crea una competencia entre el generador y el discriminador. La función muestra el progreso y, cada cierto número de épocas, genera y guarda imágenes de dígitos generados. - Generación y Guardado de Imágenes: La función
generate_and_save_imagesgenera imágenes de dígitos utilizando el generador y las guarda en un archivo de imagen. Estas imágenes se generan durante el entrenamiento para observar el progreso de la GAN. - Entrenamiento de la GAN: Finalmente, se llama a la función
train_ganpara entrenar la GAN. Durante el entrenamiento, tanto el generador como el discriminador mejoran sus habilidades, y el generador aprende a generar imágenes realistas de dígitos escritos a mano.
Epoch: 0, D Loss: 0.9474876374006271, G Loss: 1.3809154033660889 1/1 [==============================] – 0s 32ms/step

Epoch: 1000, D Loss: 0.04573569446802139, G Loss: 5.032070159912109 1/1 [==============================] – 0s 14ms/step

Epoch: 2000, D Loss: 0.2332010306417942, G Loss: 4.198168754577637 1/1 [==============================] – 0s 16ms/step

Epoch: 3000, D Loss: 0.09189734607934952, G Loss: 8.080753326416016 1/1 [==============================] – 0s 13ms/step
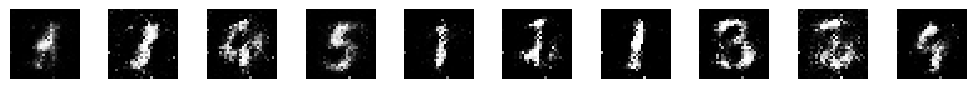
Epoch: 4000, D Loss: 0.2200010120868683, G Loss: 4.917149543762207 1/1 [==============================] – 0s 18ms/step

Epoch: 5000, D Loss: 0.08954114839434624, G Loss: 5.541191101074219 1/1 [==============================] – 0s 13ms/step

Epoch: 6000, D Loss: 0.1730344444513321, G Loss: 3.601317882537842 1/1 [==============================] – 0s 13ms/step

Epoch: 7000, D Loss: 0.23358163982629776, G Loss: 3.3358240127563477 1/1 [==============================] – 0s 16ms/step

Epoch: 8000, D Loss: 0.19538309052586555, G Loss: 4.939027309417725 1/1 [==============================] – 0s 18ms/step
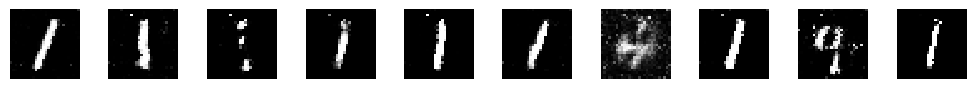
Epoch: 9000, D Loss: 0.1658102571964264, G Loss: 4.499600887298584 1/1 [==============================] – 0s 14ms/step

A medida que la GAN se entrena, el generador aprende a generar imágenes de dígitos cada vez más realistas. Este es un ejemplo muy sencillo, pero puedes ajustar los hiperparámetros y el número de épocas para obtener mejores resultados.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article. https://accounts.binance.com/cs/register?ref=S5H7X3LP
hentaifox This is really interesting, You’re a very skilled blogger. I’ve joined your feed and look forward to seeking more of your magnificent post. Also, I’ve shared your site in my social networks!
Puraburn I appreciate you sharing this blog post. Thanks Again. Cool.
Tech dae Pretty! This has been a really wonderful post. Many thanks for providing these details.
PrimeBiome I do not even understand how I ended up here, but I assumed this publish used to be great
Usually I do not read article on blogs however I would like to say that this writeup very compelled me to take a look at and do so Your writing taste has been amazed me Thanks quite nice post
gab I like the efforts you have put in this, regards for all the great content.
Noodlemagazine I appreciate you sharing this blog post. Thanks Again. Cool.
Noodlemagazine I like the efforts you have put in this, regards for all the great content.
Noodlemagazine naturally like your web site however you need to take a look at the spelling on several of your posts. A number of them are rife with spelling problems and I find it very bothersome to tell the truth on the other hand I will surely come again again.
Noodlemagazine I just like the helpful information you provide in your articles
Noodlemagazine Good post! We will be linking to this particularly great post on our site. Keep up the great writing
Tech Learner This was beautiful Admin. Thank you for your reflections.
Fantastic site Lots of helpful information here I am sending it to some friends ans additionally sharing in delicious And of course thanks for your effort
dodb buzz You’re so awesome! I don’t believe I have read a single thing like that before. So great to find someone with some original thoughts on this topic. Really.. thank you for starting this up. This website is something that is needed on the internet, someone with a little originality!
Fantastic beat I would like to apprentice while you amend your web site how could i subscribe for a blog site The account helped me a acceptable deal I had been a little bit acquainted of this your broadcast offered bright clear concept
Tech to Force I’m often to blogging and i really appreciate your content. The article has actually peaks my interest. I’m going to bookmark your web site and maintain checking for brand spanking new information.
What i do not understood is in truth how you are not actually a lot more smartlyliked than you may be now You are very intelligent You realize therefore significantly in the case of this topic produced me individually imagine it from numerous numerous angles Its like men and women dont seem to be fascinated until it is one thing to do with Woman gaga Your own stuffs nice All the time care for it up
Hi Neat post There is a problem along with your website in internet explorer would test this IE still is the market chief and a good section of other folks will pass over your magnificent writing due to this problem
allegheny county real estate Nice post. I learn something totally new and challenging on websites
allegheny county real estate I am truly thankful to the owner of this web site who has shared this fantastic piece of writing at at this place.
I have been browsing online more than three hours today yet I never found any interesting article like yours It is pretty worth enough for me In my view if all website owners and bloggers made good content as you did the internet will be a lot more useful than ever before
Fun88 là thiên đường cho những người yêu bóng đá! Nơi đây cung cấp đa dạng kèo cược bóng đá hấp dẫn, từ các giải đấu lớn như Ngoại hạng Anh, La Liga, Serie A đến các giải đấu nhỏ hơn. Fun88 mang đến cho bạn những trải nghiệm cá cược bóng đá tuyệt vời nhất! bóng đá fun88
I couldn’t agree more with the points you’ve made here. This is an outstanding article. fun88 k8 group
Real Estate I like the efforts you have put in this, regards for all the great content.
Techno rozen naturally like your web site however you need to take a look at the spelling on several of your posts. A number of them are rife with spelling problems and I find it very bothersome to tell the truth on the other hand I will surely come again again.
Ny weekly naturally like your web site however you need to take a look at the spelling on several of your posts. A number of them are rife with spelling problems and I find it very bothersome to tell the truth on the other hand I will surely come again again.
Simply desire to say your article is as surprising The clearness in your post is simply excellent and i could assume you are an expert on this subject Fine with your permission let me to grab your feed to keep up to date with forthcoming post Thanks a million and please carry on the gratifying work
I was recommended this website by my cousin I am not sure whether this post is written by him as nobody else know such detailed about my difficulty You are wonderful Thanks
you are in reality a good webmaster The website loading velocity is amazing It sort of feels that youre doing any distinctive trick Also The contents are masterwork you have done a fantastic job in this topic
My brother recommended I might like this web site He was totally right This post actually made my day You cannt imagine just how much time I had spent for this information Thanks
Your blog is a testament to your dedication to your craft. Your commitment to excellence is evident in every aspect of your writing. Thank you for being such a positive influence in the online community.
Hello i think that i saw you visited my weblog so i came to Return the favore Im trying to find things to improve my web siteI suppose its ok to use some of your ideas
What i do not understood is in truth how you are not actually a lot more smartlyliked than you may be now You are very intelligent You realize therefore significantly in the case of this topic produced me individually imagine it from numerous numerous angles Its like men and women dont seem to be fascinated until it is one thing to do with Woman gaga Your own stuffs nice All the time care for it up
I loved as much as you will receive carried out right here The sketch is attractive your authored material stylish nonetheless you command get got an impatience over that you wish be delivering the following unwell unquestionably come more formerly again since exactly the same nearly a lot often inside case you shield this hike
Nice blog here Also your site loads up very fast What host are you using Can I get your affiliate link to your host I wish my site loaded up as quickly as yours lol
I am not sure where youre getting your info but good topic I needs to spend some time learning much more or understanding more Thanks for magnificent info I was looking for this information for my mission
of course like your website but you have to check the spelling on several of your posts A number of them are rife with spelling issues and I in finding it very troublesome to inform the reality on the other hand I will certainly come back again
Usually I do not read article on blogs however I would like to say that this writeup very compelled me to take a look at and do so Your writing taste has been amazed me Thanks quite nice post
Fantastic site Lots of helpful information here I am sending it to some friends ans additionally sharing in delicious And of course thanks for your effort
Attractive section of content I just stumbled upon your blog and in accession capital to assert that I get actually enjoyed account your blog posts Anyway I will be subscribing to your augment and even I achievement you access consistently fast
This blog is also fantastic. It loads your webpage quite swiftly. Which web host do you employ? Could you please share your affiliate link with me? My page should load just as quickly as yours does.
I was recommended this website by my cousin I am not sure whether this post is written by him as nobody else know such detailed about my difficulty You are wonderful Thanks
Normally I do not read article on blogs however I would like to say that this writeup very forced me to try and do so Your writing style has been amazed me Thanks quite great post
Wonderful beat I wish to apprentice while you amend your web site how could i subscribe for a blog web site The account aided me a acceptable deal I had been a little bit acquainted of this your broadcast provided bright clear idea
It was great seeing how much work you put into it. Even though the design is nice and the writing is stylish, you seem to be having trouble with it. I think you should really try sending the next article. I’ll definitely be back for more of the same if you protect this hike.
My brother said I might enjoy this blog, and he was 100% correct. This post brightened my day. You have no idea how much time I spent searching for this information.